

精工解码
一起来解锁计算机视觉的“演化之路”
2025年,当AI医⽣通过联邦学习在3秒内完成肺结节筛查,当⾃动驾驶汽⻋用多传感器融合技术在暴⾬中识别⾏⼈,当FaceID以99.99%的准确率解锁你的⼿机——这些看似理所当然的智能体验,背后是计算机视觉60年的进化史诗。今天,我们就从计算思维的角度,来拆解这场"教会机器看世界"的伟⼤⾰命,揭秘数据、算⼒与算法如何像三驾⻢⻋,共同拉动视觉智能从梦想照进现实。
01
蒙昧探索期:像素拼图时代的盲人摸象(1960s-1990s)

首先,让我们回到1966年的夏天,MIT教授Marvin Minsky给他的本科生布置了一个看似轻松的暑期作业:“把一个摄像头连到电脑上,然后写个程序,让电脑告诉我它看到了什么。”
在当时的这群天才科学家眼里,相比于下棋、证明数学定理这些需要“高智商”的任务,“看东西”不过是眼睛接收光信号的过程,应该只是一个简单的信号处理问题。Minsky当时认为,这个问题只要找几个聪明的本科生,利用暑假两三个月的时间就能顺手解决。然而,这个暑假结束时,他们只勉强做到了从混乱的背景中把物体“抠”出来一点点。
结果是: 这个原本计划用“一个暑假”解决的作业,最终让人类顶尖科学家接力奋斗了50多年。直到 2012 年深度学习爆发,电脑才真正开始“看懂”了世界。
从计算思维的角度来看,这个阶段的核⼼思维是问题分解——把复杂的视觉任务拆解成边缘检测、角点识别等⼦问题。就像盲⼈摸象,只能感知局部,缺缺少对于全局的把握。
02
特征工程时代:手工打造的视觉密码本(1990s-2011)
1999年,计算机视觉领域发⽣了⼀件标志性事件:卡内基梅隆⼤学的研究团队⽤Viola-Jones算法实现了实时⼈脸检测。这个能在300ms内锁定⼈脸的算法,就像给计算机装上了"寻⼈雷达",让数码相机的笑脸快⻔功能成为可能。
在这一时期,数据,算力,算法三要素都发生了质的飞跃
数据规模:随着互联⽹普及,数据集⾸次突破百万级。2006年发布的LabelMe数据集包含5万张标注图像,⽽2009年的ImageNet更是⾰命性地包含1400万张图⽚,涵盖2万多个类别。数据不再是涓涓细流,开始形成可灌溉智能的河流。
算⼒演进:GPU的出现成为算⼒⾰命的第⼀声春雷。2009年,NVIDIA推出的GTX 280显卡,单精度浮点运算能⼒达1TFlops,相当于100台1990年代超级计算机的总和。这就像从⾃⾏⻋突然升级到⾼铁,算⼒的跃升让复杂特征提取成为可能。
算法创新:这个时期的算法明星是SIFT(尺度不变特征变换)和HOG(⽅向梯度直⽅图)。SIFT算法能在不同尺度、旋转⻆度下识别物体,就像⼈类⽆论从正⾯还是侧⾯都能认出朋友;HOG特征则通过统计梯度⽅向捕获边缘信息,让2005年的⾏⼈检测准确率突破80%。
特征⼯程时代的核⼼计算思维是抽象建模——把图像转化为计算机能理解的数学描述。就像古⼈⽤象形⽂字记录世界,研究者也试图⽤⼈⼯设计的特征来编码视觉信息。然而,这种手工提取特征的方法终尤其局限性,难以捕捉真实物理世界的瞬息万变,如遇到光照变化或遮挡等干扰时就会失效。那么,怎么让计算机学会自动提取特征呢?
当然是让机器拥有像人一样的神经网络!
这正是发生在2012年的故事。
03
深度学习爆发期:神经网络睁开的电子眼(2012-2020)
2012年,AlexNet在ImageNet竞赛中以84.7%的准确率震惊世界,⽐第⼆名⾼出10个百分点。这个8层深的卷积神经⽹络就像给计算机装上了"电⼦眼",第⼀次让机器真正"看⻅"了世界的丰富细节。

卷积神经网络(Convolutional Neural Networks, CNN)
看到这里,你肯定会问:什么是卷积神经网络?为什么它会如此强大?
你可以把它想象成一场进化:网络底层先学会识别线条与色块,中间层组合成纹理与部件,最高层则理解完整的物体。更重要的是,这个过程是自动的、数据驱动的——无需人工设计特征,而是通过数百万张图片的训练,让卷积核自行优化成最敏锐的“视觉探测器”。AlexNet的成功正是证明了:让模型直接从数据中学习层次化的视觉表达,远比人类手工设计的特征更强大、更通用。
这正是深度学习的核心突破——将设计规则的负担,转化为设计学习能力的智慧。
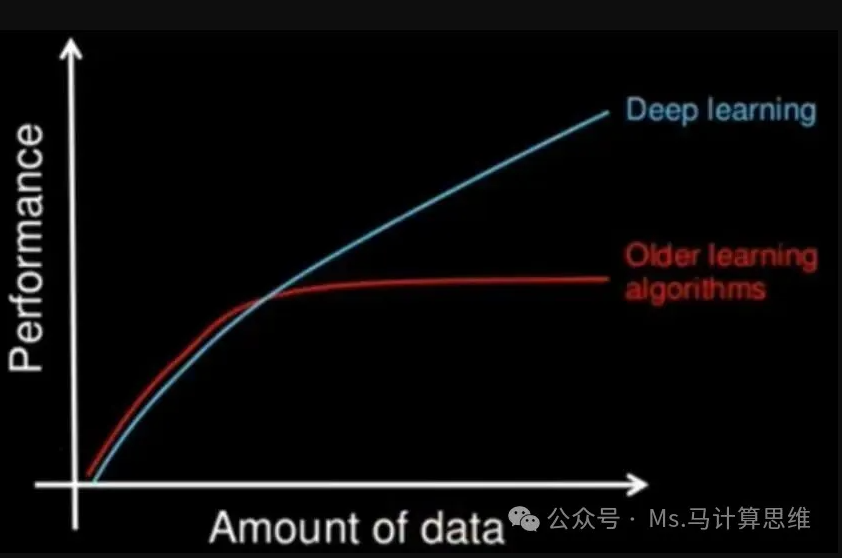
这张经典对⽐图揭⽰了转折点:当数据量较⼩时,⼿⼯特征(红⾊曲线)尚能与深度学习(蓝⾊曲线)抗衡;但当数据量超过临界点,深度学习就像挣脱束缚的⽕箭,性能曲线持续攀升,⽽传统⽅法则早早触顶。
在这个飞速发展的时期,除了算法的革命性创新,数据与算力也到达了前所未有的高度。
ImageNet数据集从2010年的120万张增⻓到2020年的1.4亿张,标注类别从1000扩展到2万。这些数据如果打印出来,⾜以覆盖整个纽约曼哈顿岛。更重要的是,数据质量实现⻜跃——ImageNet的每张图⽚都经过3名标注员交叉验证,确保标注错误率低于5%。
GPU算⼒也在这⼗年间增⻓了1000倍。2012年训练AlexNet需要两块GTX 580显卡跑⼀周;到2020年,单张A100显卡就能在1⼩时内完成同等规模的模型训练。⾕歌的TPU(张量处理单元)更是将能效⽐提升30倍,就像从⽕⼒发电升级到核电,为深度学习提供了澎湃动⼒。
深度学习时代的核⼼思维是特征学习——让机器从数据中⾃动发现特征。如果说特征⼯程是"教机器认字",那深度学习就是"让机器⾃⼰发明⽂字"。当⽹络⾃动学习到"猫须""狗⽿"这些关键特征时,AI就具备了举⼀反三的能⼒。
04
大模型与生成式AI阶段:视觉智能的成人礼(2020至今)
2023年,SAM(Segment Anything Model)模型横空出世,仅⽤10亿参数就实现零样本图像分割。这个能"点哪⼉分哪⼉"的基础模型,标志着计算机视觉进⼊"⼤模型时代"——就像⼈类从识别具体事物到掌握抽象概念,视觉AI也开始形成通⽤认知能⼒。
大模型时代下,我们正高速行驶在通往AGI
(Artificial General Intelligence)的道路上,计算机视觉也从实验室走进了人们的日常生活.....
自动驾驶:多传感器如何让AI在暴雨中"明察秋毫"
Waymo的⾃动驾驶汽⻋在2025年实现了⼀个⾥程碑:在暴⾬天⽓下,仅⽤视觉摄像头就成功识别并避让了横穿⻢路的⾏⼈。这背后是多传感器融合技术的突破——激光雷达(LiDAR)提供3D点云,毫⽶波雷达穿透⾬雾,摄像头捕捉⾊彩细节,就像⼈类⽤眼睛看、⽿朵听、双⼿触摸来感知世界,多模态信息互相印证,确保极端环境下的安全。
城市治理:全域感知如何让AI在2025年“预判风险”
深圳在2025年部署的“城市智能体”实现了一项突破:在熙攘的商业街人群中,系统提前数秒预警了一起潜在的拥挤踩踏风险,并自动调度警力疏导。这背后是全域智能感知网络的成熟——高空摄像头统览全局人流热力图,街边设备识别人脸与体态以判断情绪和意图,物联网传感器实时监测区域密度与移动速度,就像一位经验丰富的指挥官同时观看卫星图、听取前线汇报、感受战场态势,多源信息在数字孪生城市中融合推演,实现对公共安全事件的超前感知与精准干预。
零售消费:空间计算如何让AI在2025年“读懂心境”
阿里巴巴的“未来购物镜”在2025年展现了全新交互:顾客仅需对镜浏览,无需任何手动操作,系统便能通过其细微表情与目光停留,推荐最符合当下心境的穿搭,并叠加AR特效。这背后是情绪感知与空间计算技术的结合——3D摄像头精准重建人体模型,微表情识别算法解析潜意识偏好,AR渲染引擎实时生成逼真试穿效果,就像一位顶级的私人购物顾问,不仅观察你的试穿,更能解读你的眼神与神态,将沉默的浏览转化为一场沉浸式的对话。
05
视觉智能的下一站:从"看见"到"理解"
/ NEWS TODAY
当我们回顾计算机视觉60年的进化史,会发现⼀个清晰的脉络:从局部到整体,从被动识别到主动创作,从单⼀任务到通⽤智能。今天的视觉AI已经能"看⻅"像素背后的意义——看到"微笑"会感到愉悦,看到"事故"会感到担忧,看到"婴⼉"会联想到"脆弱"。这种从"视觉感知"到"情感理解"的跨越,正是下⼀代AI的突破⼝。
未来,随着多模态⼤模型的发展,视觉智能将与语⾔、⾳频等模态深度融合。想象⼀下:你的AR眼镜不仅能识别眼前的建筑,还能告诉你它的历史故事;⾃动驾驶汽⻋不仅能看到⾏⼈,还能预测他的下⼀步动作;AI医⽣不仅能检测病灶,还能解释致病机理——这些场景不再遥远。
写在最后
从拉⾥·罗伯茨的铅笔草图到SAM模型的零样本分割,从20x20像素的积⽊图像到10亿参数的视觉⼤模型,计算机视觉的60年,是⼀部⼈类教会机器"看"世界的史诗。⽽这部史诗最动⼈的地⽅在于:我们不仅创造了智能,更在这个过程中重新认识了"看⻅"本⾝的意义——看⻅不仅是接收光线,更是理解、共情与创造。这或许就是AI给⼈类最好的礼物:通过教会机器看世界,我们重新发现了世界的美好!
转自:Ms.马计算思维