

制造创新
论文地址:https://arxiv.org/abs/2412.04453
项目地址:https://navila-bot.github.io/
贡献(Contributions)
🤖 该论文提出了NaVILA,一个用于解决足式机器人视觉-语言导航(VLN)问题的两层框架,旨在将人类指令高效转化为复杂环境中的低级腿部动作。
💡 NaVILA通过一个高层视觉-语言-动作(VLA)模型生成中级语言指令,再由一个实时视觉运动强化学习策略负责低级动作执行,实现了高层推理与低级控制的解耦。
🚀 NaVILA在VLN-CE基准测试中显著超越现有方法,并在现实世界足式和人形机器人上成功执行长距离复杂指令导航,展现了强大的泛化能力和鲁棒性。
摘要(Abstract)
该论文提出了 NaVILA,一个专为腿式机器人设计的视觉-语言-动作(VLA)模型,旨在解决其在复杂且杂乱环境中进行视觉-语言导航(Vision-and-Language Navigation, VLN)的难题。传统方法难以将人类语言指令直接转化为低级关节动作,而 NaVILA 通过一个双层框架巧妙地将 VLA 模型与运动技能相结合。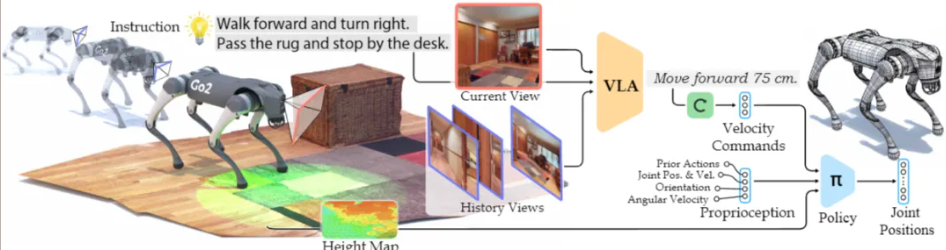 核心方法(Core Methodology)
核心方法(Core Methodology)
NaVILA 的核心在于其两层架构设计:
高级 VLA 模型(High-level VLA Model):一个基于 Vision-Language Model (VLM) 的模型,负责理解人类语言指令和视觉观测,并生成中级动作指令。
低级视觉运动策略(Low-level Visual Locomotion Policy):一个强化学习(RL)策略,负责将中级动作指令转化为精确的机器人关节运动,并在实时环境中执行。 Fig.2 驯化VLM作为上层规划器
Fig.2 驯化VLM作为上层规划器
A. 驯化 VLM 进行视觉语言导航
VLM 选择与处理视频输入:
鉴于当前高质量视频-文本数据集的稀缺性,NaVILA 选择了基于图像的 VLM(具体是 VILA 系列模型),以利用其在图像-文本数据上训练获得的强大泛化能力和多图像推理能力。
为了有效处理视频输入(即序列图像作为观测),NaVILA 不采用 VILA 统一采样帧的方式,而是将最新帧 作为当前观测,而从之前的 帧中均匀采样帧作为历史观测(内存库),并始终包含第一帧。
通过文本提示词(如 a video of historical observations: 和 current observation:)在任务提示中区分这两种观测,避免引入额外的特殊 token,以充分利用预训练 LLM 的推理能力。
导航任务提示的格式为: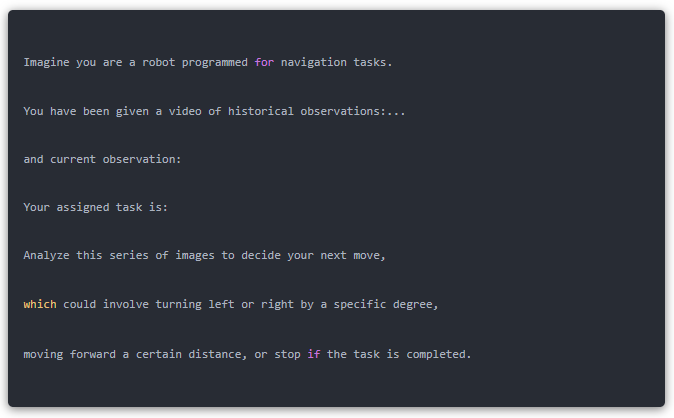
VLM 的输出是自然语言形式的中级动作指令,例如 “Move forward 75 cm.” 或 “Walk forward and turn right. Pass the rug and stop by the desk.”。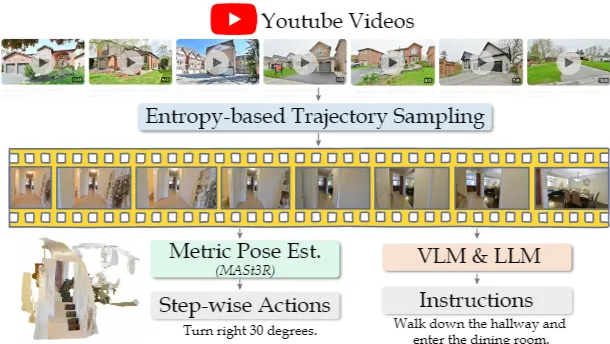
Fig.3 从YouTube人类视频中学习导航技巧
从人类视频中学习:
NaVILA 创新性地利用 YouTube 上的 2K 个 egocentric 人类旅游视频来直接训练连续导航模型,这在以往的离散导航设定中较为困难。
数据处理流程:
通过基于熵的采样从视频中提取 20K 条具有代表性的轨迹。
使用 MASt3R 进行度量姿态估计,提取每一步的动作。
结合 VLM 生成轨迹描述,再通过 LLM 进行复述,生成自然语言指令。
监督微调(SFT)数据混合:
为了提升模型在具身任务中的专业性、避免过拟合特定动作、并增强对真实世界场景的泛化能力,NaVILA 设计了一个包含四种来源的 SFT 数据混合:
来自真实视频的导航数据:即上述从 YouTube 人类视频中提取的数据。
来自模拟环境的导航数据:利用 Habitat 模拟器中的 R2R-CE和 RxR-CE数据集。通过最短路径追踪器生成动作序列,并将连续动作合并(最多三个),以增加动作多样性并减少数据量。同时,对 stop 动作进行再平衡处理以解决标签不平衡问题。
辅助导航数据:采用 EnvDrop的增强指令,并引入导航轨迹摘要辅助任务,即给定轨迹视频,LLM 根据采样帧描述机器人的轨迹。此外,集成 ScanQA 数据集以增强空间场景理解。
通用 VQA 数据集:纳入 [23, 33, 34] 中的通用 VQA 数据集,以保持模型的通用能力。
训练与推理范式:
训练始于 VILA 的第二阶段模型(已完成视觉语言语料预训练)。
然后使用上述 SFT 数据混合对整个 VLM 进行一个 epoch 的训练,所有模块(视觉编码器、连接器、LLM)均解冻。
推理时,使用正则表达式解析器从 LLM 输出中提取动作类型及其参数(如距离、角度),并经验性地发现所有动作都能成功匹配和映射。
B. 视觉运动策略
机器人平台:主要实验平台为 Go2 机器狗,配备 LiDAR 传感器,具有 18 个自由度(DoFs),策略控制腿部 12 个关节电机。
解释高级指令:VLM 输出的中级指令(如 {move forward, turn left, turn right, stop})被转换为固定指令速度,例如前进 0.5 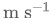 、左转
、左转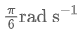 、右转
、右转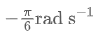 、停止 0,并执行相应时长。
、停止 0,并执行相应时长。
低级动作与观测空间:
动作空间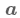 定义为期望关节位置
定义为期望关节位置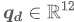 ,通过刚度和阻尼转换为模拟器扭矩输入。
,通过刚度和阻尼转换为模拟器扭矩输入。
使用 PPO 算法 [37] 训练策略。Critic 观察特权环境,Actor 仅接收真实世界可用的传感器数据。
Critic 观测 包含本体感受信息、当前指令速度和特权地形高度图。本体感受数据包括机器人线速度、角速度、姿态、关节位置、关节速度和前一动作。
包含本体感受信息、当前指令速度和特权地形高度图。本体感受数据包括机器人线速度、角速度、姿态、关节位置、关节速度和前一动作。
Actor 观测 不包含线速度(真实世界不可用),而是通过历史本体感受数据隐式推断。
不包含线速度(真实世界不可用),而是通过历史本体感受数据隐式推断。
机器人使用 LiDAR 传感器生成的高度图感知周围地形,LiDAR 能有效检测透明物体并在强阳光下表现稳定。
训练:
NaVILA 采用单阶段强化学习方法训练运动策略,与大多数两阶段(教师-学生)训练方法 [38–41] 不同。单阶段 RL 更高效,且策略可以直接与环境交互,探索新策略。
利用 Isaac Lab 中的光线投射功能,视觉 RL 策略训练在 RTX 4090 GPU 上实现了超过 60K FPS 的高吞吐量。
奖励函数和域随机化参数在补充材料中详细列出。
实验结果
高级 VLA 性能:
在 VLN-CE 基准测试(R2R-CE 和 RxR-CE 的 Val-Unseen 分割)中,NaVILA 显著超越了所有不依赖模拟器预训练路点预测器的 SOTA 基线,成功率 (SR) 提升超过 17%。
值得注意的是,NaVILA 仅使用单视图 RGB 输入,其性能与使用全景视图、里程计或预训练路点预测器的模型相当或更优,表明其强大的泛化能力有效弥补了有限观测的不足。
在跨数据集泛化(R2R 训练,RxR Val-Unseen 零样本评估)中,NaVILA 同样显著优于 SOTA 模型 NaVid [12],SR 提升了 10%。
在 ScanQA 空间场景理解基准测试中,NaVILA 显著优于 NaviLLM [60](CIDEr 分数高 20 分),并且在使用 64 帧时,性能超越了需要 3D 扫描或 RGBD 数据作为输入的 3D LMMs [61, 62]。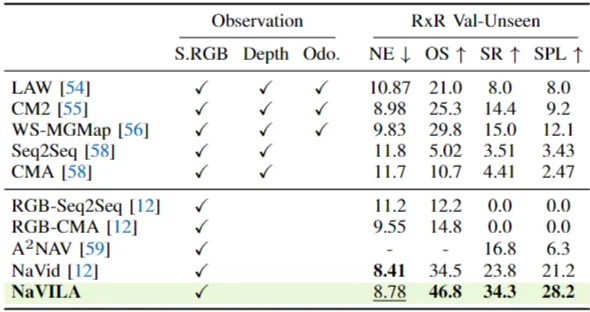
低级 RL 策略性能:
NaVILA 的低级策略在 Isaac Sim 中与基于策略蒸馏的 ROA [68] 进行了比较,在线速度误差、角速度误差和碰撞率三个指标上均表现更优,特别是碰撞率显著降低,验证了其训练方法的有效性。
腿式机器人模拟导航性能 (VLN-CE-Isaac)
引入了新的高保真基准测试 VLN-CE-Isaac (基于 Isaac Sim),考虑了详细的机器人关节运动和环境交互。
在此基准测试中,视觉策略相比仅基于本体感受的(盲)策略,在 Go2 机器人上成功率提升 14%,在 H1 机器人上提升 21%,这归因于其卓越的避障能力。
NaVILA 也展示了在 Go2 和 H1 机器人上的跨平台部署灵活性。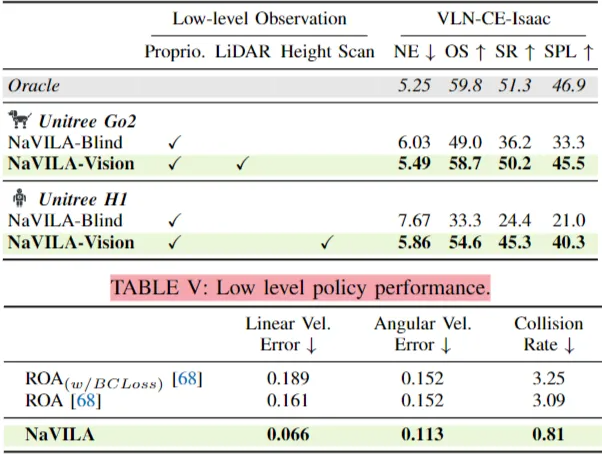
真实世界评估:
NaVILA 在真实世界中对 Go2 机器狗和 Booster T1 人形机器人进行了 25 条指令(每条重复三次)的测试,涵盖简单和复杂任务,以及“Workspace”、“Home”和“Outdoor”等多样环境。
NaVILA 在 SR 和 NE 上均显著优于 SOTA VLM GPT-4o。
消融实验表明,人类视频数据显著提高了模型在室外场景的泛化能力及所有环境的成功率。
NaVILA 的双层方法展现了很强的灵活性和泛化能力,即使在相机高度和视角发生变化的 Booster T1 人形机器人上,无需重新训练 VLA 模型也能保持出色性能。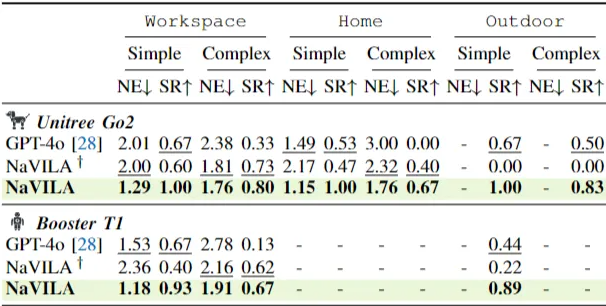
结论与局限性
NaVILA 成功地将 VLA 模型与运动技能相结合,实现了通用导航。其通过生成高级语言指令,并由实时运动策略处理避障,增强了在不同机器人上的鲁棒性。这种设计保留了推理能力,避免了过拟合,并支持从人类视频中直接学习以提高泛化。NaVILA 在经典 VLN 基准测试上实现了 17% 的性能提升,在低级策略上超越了基于蒸馏的方法,在 VLN-CE-Isaac 基准测试上优于视觉盲策略,并在多样环境和腿式机器人上展示了强大的真实世界性能。
尽管 NaVILA 表现出色,仍存在局限性。在某些真实世界案例中,机器人未能有效纠正偏差导致任务失败。未来的工作可以探索通过在更真实的模拟环境中进行大规模训练,以及在训练中融入显式推理数据来增强泛化能力和空间理解。此外,基于图像的 VLM 计算密集,未来长上下文 LLM 的发展有望通过更高效的序列处理来缓解这一问题。
来源:RoboticsUnleashed