

质量金标
作者丨具身纪元
本文只做学术分享,如有侵权,联系删文
Jim Fan在X上发布了一篇文章,讲述了第二种预训练范式,是用于机器人的、预测下一个物理状态的世界模型。我们翻译如下。
“预测下一个词”是第一种预训练范式。
现在,我们正经历第二种预训练范式转移:世界模型(World Modeling),即“预测下一个物理状态”。

很少有人明白这一转变影响有多深远。
遗憾的是,目前世界模型最热门的用例却是一些用AI生成的垃圾视频(接下来会是垃圾游戏)。
我敢肯定,2026年将是大型世界模型为机器人技术、以及更广泛的多模态AI奠定真正基础的元年。

在此背景下,我将世界模型定义为:基于某个动作,预测下一个合理的世界状态(或更长的一连串状态)。
视频生成模型就是一种体现。
这里的“下一个状态”是一系列RGB帧(通常8-10秒,最长几分钟),“动作”则是描述要做什么的文本。
训练过程涉及对数十亿小时视频像素的未来变化进行建模。
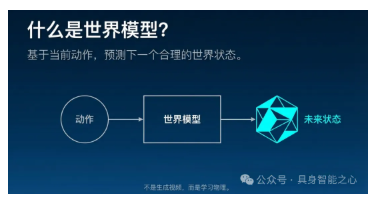
核心在于,视频世界模型是可学习的物理模拟器和渲染引擎。
它们捕捉“反事实”——换个高级点的词,就是推演如果采取不同动作,未来会如何不同。
世界模型本质上是“视觉优先”的。
相比之下,视觉语言模型(VLM)本质上是“语言优先”的。
从最早的原型(如2023年的LLaVA)开始,套路基本一致:视觉信息进入编码器,然后被路由到语言骨干网络中。
虽然随着时间推移,编码器在进步,架构变简洁,视觉也试图变得更“原生”(如Omni模型),但它仍是二等公民。
相比大语言模型(LLM)多年积累的肌肉,视觉显得微不足道。
这条路很方便。
我们知道LLM能扩展(Scale)。
我们的架构直觉、数据配方设计和基准指导(VQA),全都是针对语言优化的。

对于物理AI,2025年是VLA(视觉-语言-动作)模型的一年:在预训练的VLM检查点上嫁接一个机器人运动动作解码器。
实际上这是“LVA”:语言 > 视觉 > 动作,地位依次递减。
这条路同样方便,因为我们对VLM的配方很熟。
然而,VLM的大部分参数分配给了“知识”(例如“这团像素是可口可乐品牌”),而不是“物理”(例如“如果你倾斜瓶子,液体会流出变成棕色水洼,弄脏白桌布,搞坏电机”)。
VLA在知识检索上设计得很好,但在关键能力上重心放错了位置。这种多阶段的嫁接设计,也违背了我对简洁和优雅的偏好。

从生物学角度看,视觉主导了我们大脑皮层的计算。
大约三分之一的皮层(跨越枕叶、颞叶和顶叶区域)专门处理像素。
相比之下,语言依赖的区域相对紧凑。
视觉是连接大脑、运动器官和物理世界的最高带宽通道。它闭合了“感觉运动回路”——这是机器人技术最需要解决的回路,中间完全不需要语言参与。
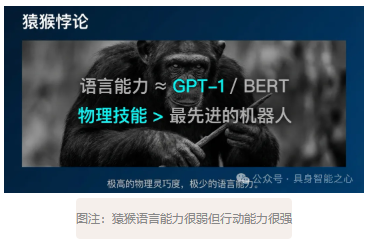
大自然给了我们一个存在证明,即具备极高灵巧度的物理智能,却只有极少的语言能力:猿猴。
我见过猿猴开高尔夫球车,像人类技工一样用螺丝刀换刹车片。它们的语言理解能力顶多相当于BERT或GPT-1,但物理技能却远超我们最先进的机器人。
猿猴可能没有好的语言模型,但它们脑中肯定有一幅强大的“如果……会怎样”的图景:物理世界是如何运作的,以及如何对它们的干预做出反应。
世界模型的时代到了。它印证了“苦涩的教训”(The Bitter Lesson)。
正如Jitendra喜欢提醒我们这些沉迷于扩展(Scaling)的人那样:“监督是AI研究人员的。”整个YouTube和智能眼镜的兴起,将捕捉到海量的世界原始视觉流,其规模远超我们要训练的所有文本。
我们将看到一种新型的预训练:下一个世界状态包含的将不仅仅是RGB图像——还包含3D空间运动、本体感觉和触觉感测,这些才刚刚起步。
我们将看到一种新型的推理:视觉空间中的“思维链”,而不是语言空间中的。你可以通过模拟几何形状和接触,想象物体如何移动和碰撞来解决物理谜题,完全无需翻译成字符串。语言是瓶颈,是脚手架,而非地基。

我们将面临新的潘多拉魔盒,充满未解之谜:即使有了完美的未来模拟,该如何解码运动动作?像素重建真的是最佳目标吗?还是应该进入某种替代的潜空间?我们需要多少机器人数据?大规模遥操作仍然是答案吗?
做完这些练习后,我们是否终于迈向了机器人的“GPT-3时刻”?
Ilya终究是对的。AGI尚未收敛。我们回到了研究的时代,没有什么比挑战第一性原理更令人兴奋的了。