
量子跃迁者
这节课老师带领我们了解了目标检测的定义、任务目标、基本原理、基本概念,回顾了目标检测模型各个阶段的发展和成果及一些实际训练中会用到的算法及算法改进思路。整体我觉得这节课比较提纲挈领,让我们一起来看看讲了什么:
目标检测的定义:给定一张图片,用矩形框框出所有感兴趣物体同时预测物体的类别。
应用场景
照片中识别人脸区域,分析人的属性
智慧城市应用:垃圾检测、非法占道检测、违章停车检测、危险物体检测、烟雾和火灾监测、着装监测、违规吸烟检测、危险行为检测
自动驾驶:环境感知、路径规划与控制
目标检测的下游任务及应用包括:
OCR:先使用目标检测检测出文字出现的区域,再进一步识别区域中的文字
人体姿态估计:先检测出图片中人体出现的位置,再进行单人姿态估计
目标检测任务和图像分类的异同
图像分类 目标检测 不同点 通常只有一个物体
物体通常位于图像中央
物体通常占据主要面积图片中:
物体数量不固定
物置不固定
物体大小不固定相同点 需要算法理解图像内容(深度神经网络实现) 目标检测的基础原理
设置一个固定大小的窗口,这个窗口叫做“滑窗(Sliding Window)”,然后使用这个滑窗遍历图像所有位置,所到之处用分类模型识别窗口中的内容;但滑窗的复杂度过高,计算成本较高,因此有两种改进思路,目前普遍采用卷积网络实现密集预测的方式来进行计算。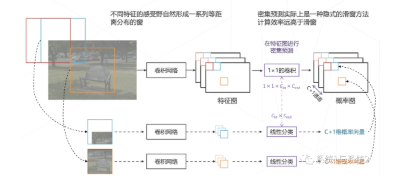
目标检测的基本范式:通过主干网络(backbone)提取图像特征,通过检测头(Head)产出分类。目前主要的目标检测方法分为两类:
两阶段方法(先以某种方式产生窗,再基于窗口内的特征进行预测),此种方法的优势是精度较高,但推理速度较慢。
单阶段方法(在特征图上基于单点特征实现密集预测),此种方法推理速度较快。
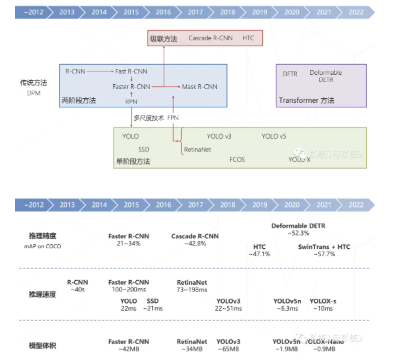
目标检测的技术演进
传统方法:DPM
两阶段方法:
R-CNN
Fast R-CNN(2015)
Faster R-CNN(里面有RPN,是一个密集预测范式的东西)
单阶段方法,包括YOLO、SSD,目前单阶段方法使用较多
后面使用多尺度技术(FPN)提升了两阶段、单阶段算法的精度,产生了RetinaNet、YOLO v3、YOLO v5
二阶段方法后续也有一定的升级,形成了级联方法如Cascade R-CNN
Transformer方法
目前目标检测的精度基本能做到60%以上,推理速度上面,YOLO系列主打速度快,而模型体积则越来越小。
目标检测的基础知识
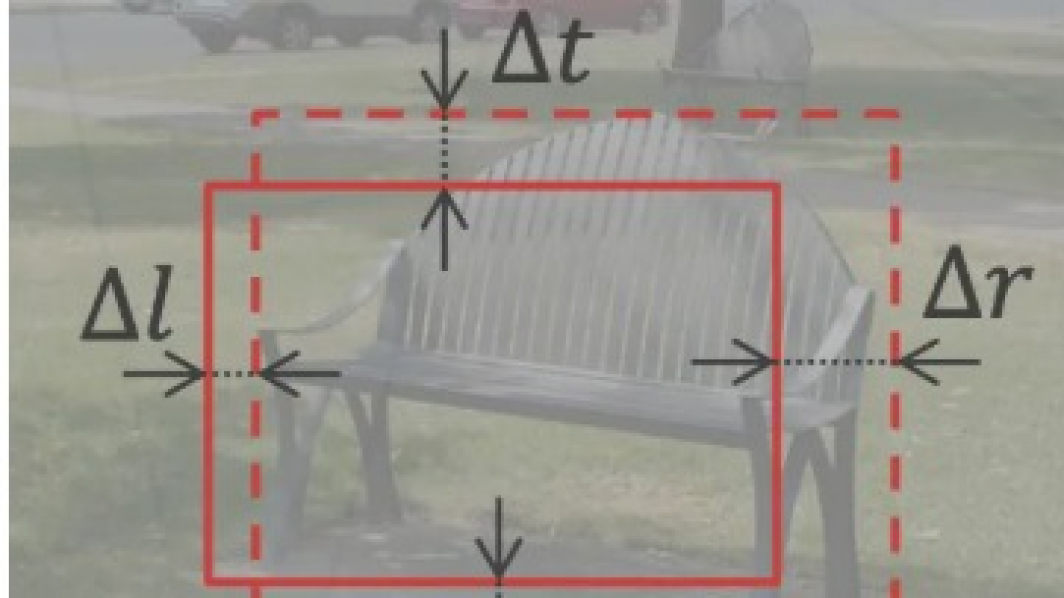
边界框(bounding box),描述边界框有两种方式,一种方式是通过框的左上右下边界坐标定义(l,t,r,b),另一种方式是通过中心坐标及框的长宽来定义(x,y,w,h)
评价指标:IOU(交并比),即检测框和标注框的交集占并集的比例,是矩形框重合程度的衡量指标。IOU的值不能超过1
置信度:在目标检测任务中通常取预测结果的概率。
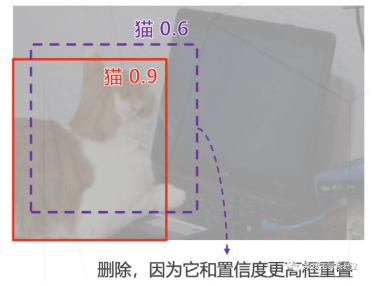
非极大值抑制(Non-Maximum Suppression):实际预测过程中,针对同一个检测目标,可能会存在多个检测框,而我们的预测结果仅保留置信度最高的一个即可,这个算法就是非极大值抑制。(如图,通过NMS把紫色的框丢掉)
边界框回归:由于滑窗和物体的精准边界通常有偏差,因此同时让模型学习预测边界框对于滑窗的偏移量
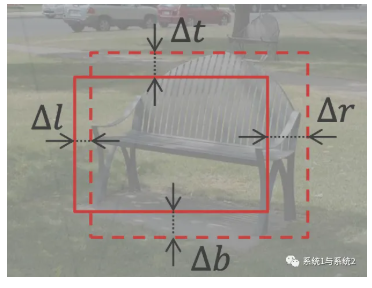
课程后面还介绍了两阶段目标检测算法的概述、典型算法说明等,这里就不详细展开了。
来源:系统1与系统2