

发条幻影
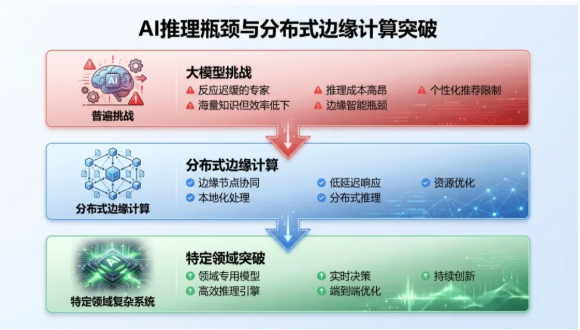
回望2025年人工智能产业全面爆发,中国MaaS(模型即服务)市场规模实现了4至5倍的增长,行业预判2026年增速有望达到10倍。在这一背景下,AI技术重心正从模型训练向大规模推理端(Inference)迁移。然而,工业界在推进AI落地时面临着严峻的挑战:大语言模型(LLM)的显存墙瓶颈、边缘设备算力的碎片化、以及推荐系统在高并发下的长尾延迟。
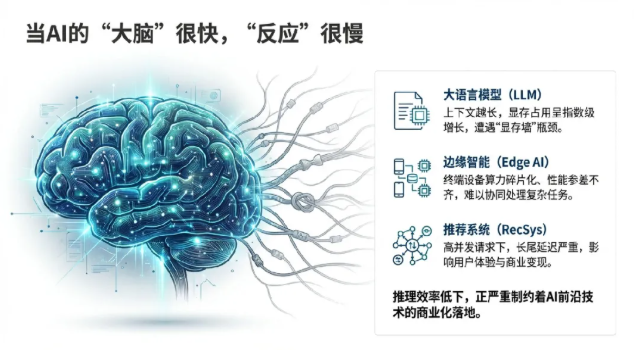
如果把一个强大的AI模型比作一位知识渊博但反应迟缓的专家,那么它虽然拥有海量的知识,但在你需要答案时却总是慢半拍。这就是当前AI领域普遍面临的“推理瓶颈”——模型在完成训练后,实际应用(推理)过程速度慢、成本高昂。
推理效率的低下,正严重制约着大语言模型、边缘智能、个性化推荐等前沿技术的商业化落地。当每一次用户交互都需要漫长的等待和高昂的计算资源时,再强大的AI也难以发挥其全部价值。
北京邮电大学网络智能研究中心王敬宇教授团队立足于国家战略需求与产业痛点,深耕“人工智能+通信网络”交叉领域,在模型推理加速方面取得了一系列突破性成果。
大语言模型推理能效的
极限突破与缓存管理创新
在2025年的AI行业中,“推理”成为核心关键词,尤其是以DeepSeek-R1为代表的推理大模型涌现,对底层算力平台的吞吐量提出了更高要求。针对大模型推理过程中序列长度增加导致的显存爆炸(KV Cache)以及异构廉价设备上的并行瓶颈,团队从流水线并行、稀疏注意力聚类及无损解码等维度构建了全方位加速体系。
01
异构廉价设备上的Token维度流水线并行框架技术创新
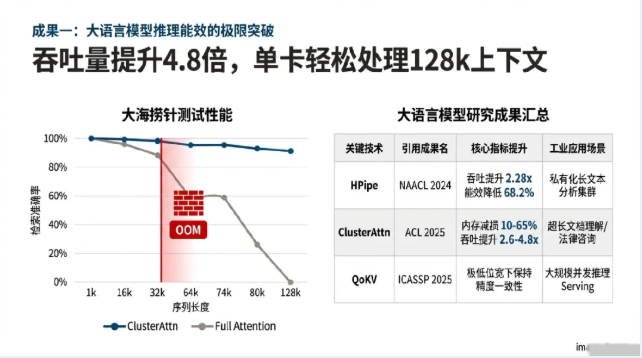
针对微型企业及个人开发者难以负担高性能计算集群的现状,团队研发了HPipe框架(HPipe: Large Language Model Pipeline Parallelism for Long Context on Heterogeneous Cost-effective Devices, NAACL 2024)。传统的流水线并行通常在批次(Batch)维度进行数据切分,但在显存受限的廉价异构设备上,过小的Batch Size限制了并行空间的发挥。HPipe创新性地提出了在Token维度进行流水线并行,将长上下文序列切分为多个片段(Segments),并利用动态规划算法(Dynamic Programming)在异构硬件间实现最优的工作负载分配。
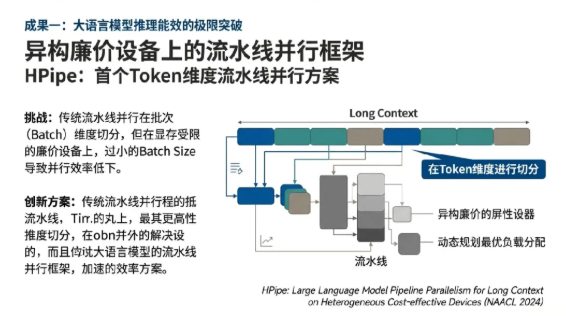
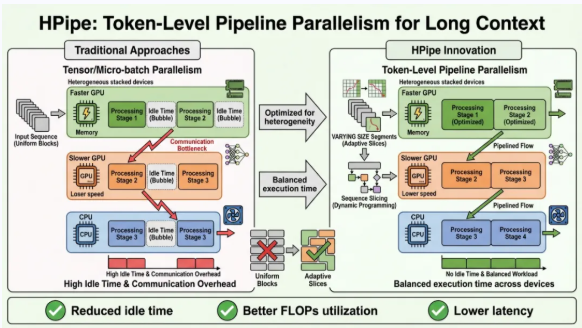
该技术通过屏蔽设备间的算力差异与不稳定的网络互连,实现了长序列推理任务在商用设备集群上的平滑演进。实验数据显示,在LLaMA-7B和GPT3-2.7B等典型模型上,HPipe在保证精度的前提下,实现了高达2.28倍的延迟缩减与吞吐提升,同时将能效消耗大幅降低了68.2%。这一创新解决了长文本分析任务在私有化部署中的“设备贵、互联难”痛点,具备极强的工业推广冲击力。
02
基于注意力内生聚类的KV缓存无损压缩技术创新
随着上下文长度迈向128k甚至更长,键值(KV)缓存已成为LLM推理系统吞吐量的头号杀手。团队在ClusterAttn(ClusterAttn: KV Cache Compression under Intrinsic Attention Clustering, ACL 2025)研究中有个反直觉的发现:LLM的注意力是“抱团”的,而非“均匀”的。注意力头在解码过程中并非盲目关注所有Token,而是表现出显著的“内生聚类”特征。通过在Prompt末端设置观察窗口,ClusterAttn能够实时捕捉这些特征簇,并利用基于密度的聚类算法自适应地压减非核心缓存。
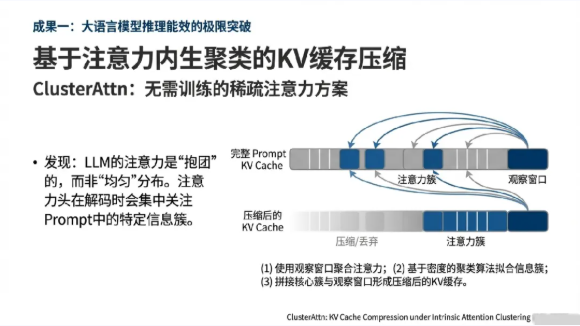
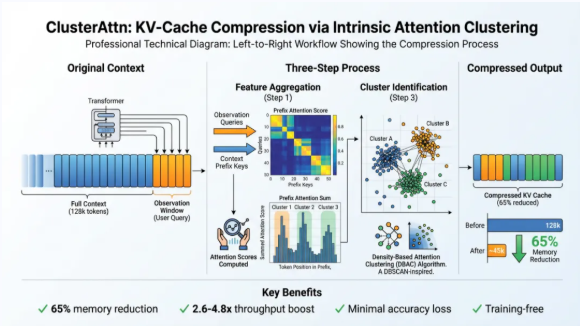
与传统的均匀量化或盲目丢弃策略不同,ClusterAttn是一种无需训练的稀疏注意力方案。它使单张A100-80GB显卡能够轻松处理128k的超长上下文,在显著减少10%至65%内存占用的同时,将推理延迟降低了12%至23%,吞吐量更是提升了2.6至4.8倍。这一技术为工业界在有限硬件资源下处理长文档摘要、超长代码理解等任务提供了最优路径。
03
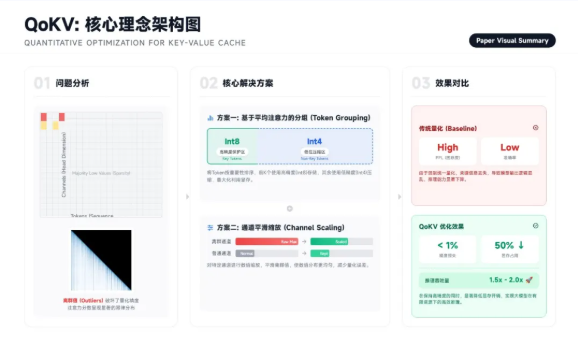
KV缓存量化障碍突破与精度保持技术创新
量化是降低LLM显存占用的事实标准,但量化带来的精度损失常导致工业级应用失效。团队在QoKV(QoKV: Comprehending and Surpassing the Hurdles of KV Cache Quantization, ICASSP 2025)中,深入探讨了KV缓存量化的核心瓶颈。通过对量化误差分布的精细化建模,团队提出了一套能够自适应调整量化比特位的策略,确保在极低位宽(如4-bit或更低)下,模型的逻辑推理与语义生成能力依然稳健。
异构边缘智能协同推理的
架构重塑与调度优化
在工业视觉、智能驾驶及智慧矿山等场景下,图像数据的海量生成与边缘端算力的贫瘠构成了长期矛盾。从优化单个大系统,我们进一步迈向了更具挑战性的分布式环境——让AI在资源受限的边缘设备上高效协同。我们团队针对卷积神经网络(CNN)的异构协同推理,从算子空间独立性、动态图分区及端云流转调度等方面提出了体系化解决方案。
01
面向异构边缘集群的分区图协同推理框架技术创新
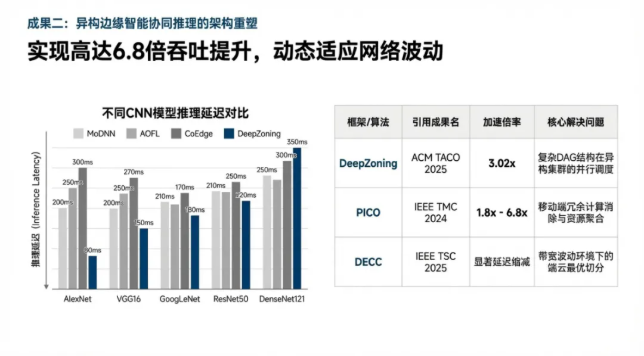
工业边缘集群通常由不同代际的GPU、DSP及FPGA组成,如何在这类高度异构的环境中寻找最优的并行粒度是一个NP-Hard难题。团队提出的DeepZoning框架(DeepZoning: Re-accelerate CNN Inference with Zoning Graph for Heterogeneous Edge Cluster, ACM TACO 2025)通过引入“分区图”(Zoning Graph)概念,完美融合了模型并行与数据并行的优势。
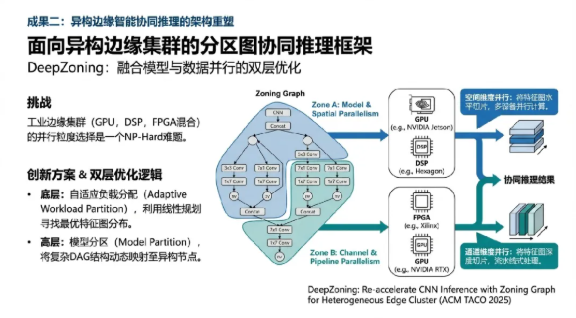
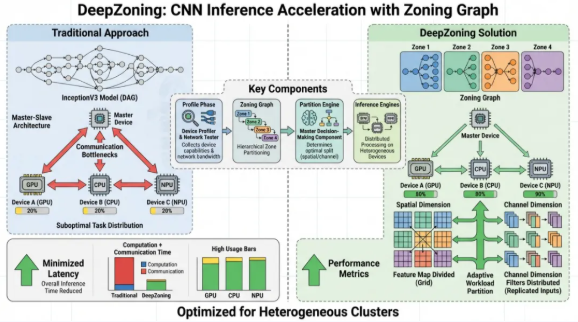
DeepZoning包含两层优化逻辑:在底层,利用线性规划算法在空间和通道维度上搜索最优的特征图分布(Adaptive Workload Partition);在高层,通过模型分区算法将复杂的Directed Acyclic Graph (DAG) 结构动态映射至异构节点。实验结果显示,在处理ResNet、YOLO等典型工业视觉模型时,DeepZoning相比于现有SOTA算法实现了高达3.02倍的推理加速 7。这为制造业自动化流水线上的多摄像头协同检测提供了极具竞争力的技术方案。
02
基于空间独立性的流水线协作推理技术创新
针对移动设备(如树莓派、手持终端)集群,团队研发了PICO框架(PICO: Pipeline Inference Framework for Versatile CNNs on Diverse Mobile Devices, IEEE TPDS 2024)。PICO敏锐地捕捉到了卷积操作的“空间独立性”,将输入特征图切分为多个Tiling,并在异构节点间构建多级流水线。
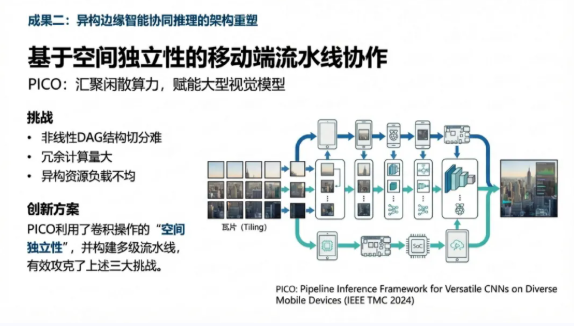
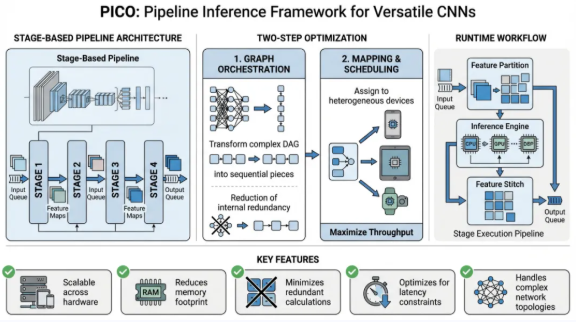
PICO攻克了非线性DAG结构切分难、冗余计算量大、异构资源负载不均三大挑战。在由8台树莓派组成的真实测试床中,PICO在不同频率环境下实现了1.8至6.8倍的吞吐量提升 10。该技术的价值在于,它能够将闲散的边缘算力汇聚成虚拟的高性能计算池,在保障隐私(数据不出本地)的同时,赋予了普通终端运行大型视觉模型的能力。
03
时延感知的端云协同与近无气泡流水线优化技术创新
在网络带宽剧烈波动的工业互联环境下,静态的模型切分方案往往导致严重的延迟波动。团队设计的DECC算法(DECC: Delay-Aware Edge-Cloud Collaboration for Accelerating DNN Inference, IEEE TSC 2025)引入了动态分区决策机制。通过在线测量iperf带宽并结合轻量级性能估算模型,DECC能够将DNN划分为多个独立分支,并在端侧与云侧建立“近乎无气泡”的流水线。
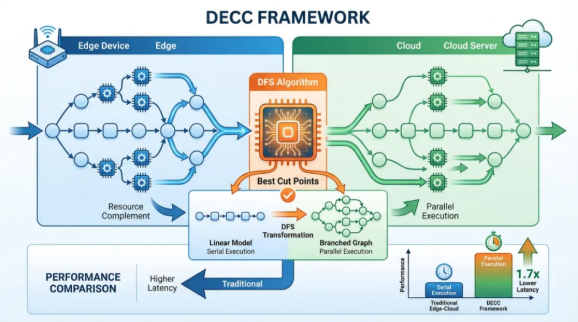
DECC不仅优化了迁移延迟,还实现了实时DNN查询的高效响应。在AlexNet、Inception V3等模型上的广泛实验证明,DECC能根据硬件配置(如1核1.2GHz至4核1.8GHz)动态调整策略,显著提升了自动驾驶、智慧医疗等时延敏感型应用的可靠性。
工业级大规模推荐系统的
全链路加速与流式调度
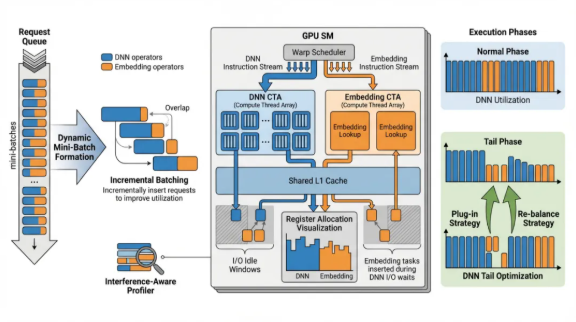
最后,我们把目光投向了AI应用中结构最复杂、优化难度最高的领域之一——推荐系统,这里的挑战要求我们超越传统的并行化思维。推荐系统作为互联网工业的流量引擎,其推理性能直接关系到企业的商业变现能力。团队针对推荐模型(RM)有的Embedding查找开销及高并发查询下的GPU竞争问题,从算子编排与全流建模角度实现了深层次优化。
01
推荐系统高并发 Serving 下的算子编排技术创新
在Web级推荐系统中,GPU需要同时处理成百上千个并发查询。传统的查询级算子分发机制会导致严重的算子碎片化与显存带宽浪费。团队研发了RACE框架(RACE: Operator Choreography for Inference Acceleration in Personalized Recommender System, SPAA 2025)。该框架通过“算子编排”技术,将Embedding查找与MLP计算等不同性质的任务进行交叉调度与重组。
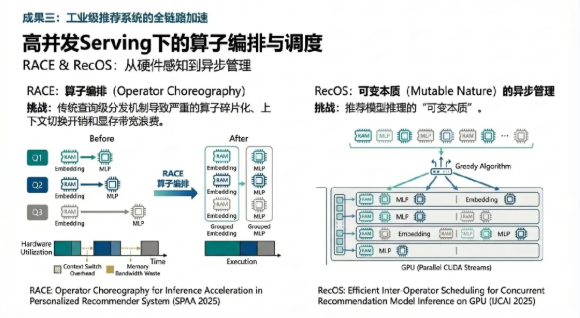
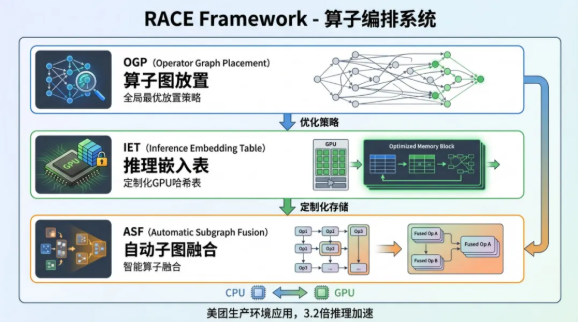
RACE的创新点在于它能够感知底层硬件的并发执行单元特性,通过最小化上下文切换开销,在复杂的Web推荐场景中实现了3.2倍的推理加速 16。这一提升直接增强了工业级推荐引擎的实时吞吐能力,缩短了广告精准触达的反馈回路。
02
基于 GPU 流式调度的并发推理优化技术创新
针对工业界广泛存在的GPU利用率不均衡问题(即Embedding层内存受限而全连接层计算受限),团队推出了RecOS系统(Efficient Inter-Operator Scheng for Concurrent Recommendation Model Inference on GPU, IJCAI 2025)。RecOS首次揭示了推荐模型推理中的“可变本质”(Mutable Nature),即在多流访问共享内存时的冲突问题。

RecOS通过实时监测GPU工作负载,采用贪心算法将算子分配至最合适的CUDA流,并引入了统一的异步张量管理机制以消除同步开销。在BST等主流推荐模型上的评估显示,RecOS在极高并发环境下(如30个并行客户端)仍能将延迟降低68% 17。这意味着在同样的成本下,企业能够承载数倍于以往的线问量。
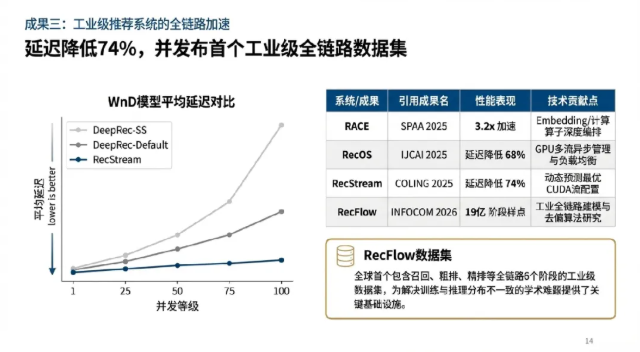
RecStream 是一个针对 推荐模型(RM)在线推理 场景设计的 流管理系统,旨在解决高并发请求下因默认 CUDA 流调度(FCFS 机制)导致的 GPU 资源竞争与延迟激增 问题。
通过两层 GCN 提取图嵌入(Graph Embedding),并结合当前并发级别的向量表示,系统能针对不同模型和负载动态预测出 最优的 CUDA 流配置。

在真实工业模型(如 WnD 系列)的评估中,RecStream 相比传统的单流或固定多流 Serving 框架,能 降低高达 74% 的推理延迟。
03
全链路工业推荐数据集RecFlow与多阶段一致性建模
除了架构优化,团队还致力于解决训练与推理分布不一致(Selection Bias)的学术难题。通过与头部视频平台合作,团队发布了RecFlow数据集(Full Stage Learning to Rank: A Unified Framework for Multi-Stage Systems, ICLR 2025)。RecFlow是全球首个包含召回、预排、粗排、精排、重排及边缘排等全链路6个阶段的工业级数据集,涵盖3800万交互与19亿个阶段样点.
利用RecFlow,团队揭示了“未曝光样本”对模型泛化性的巨大影响,并设计了一系列多阶段一致性算法。相关成果已在线上环境部署,取得了显著的业务收益(如点击率、停留时长等指标的全面提升)。这不仅是学术上的创新,更是产学研深度融合、解决真实工业难题的典型范例。
产学研深度融合与工业化部署能力
01
卓越的科研沉淀与强大的技术转化
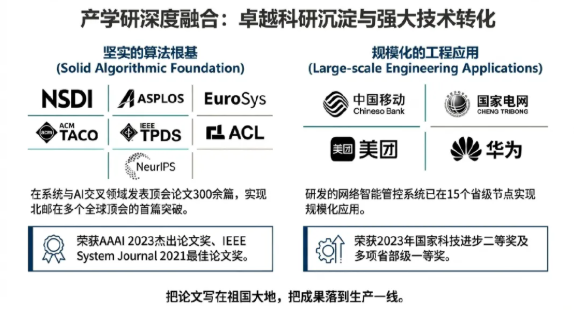
北京邮电大学网络智能研究中心NIRC团队始终坚持“把论文写在祖国大地、把成果落到生产一线”。团队产学研积累深厚,在ACM TACO、IEEE TPDS、IEEE ToN、JSAC等顶级期刊以及USENIX NSDI、ACM ASPLOS、EuroSys、INFOCOM、NeurIPS、ACL等顶级会议发表高水平论文300余篇。特别是在系统架构与人工智能交叉领域,实现了北邮在NSDI、ASPLOS、SIGMOD、EuroSys、CSCW等全球顶会上的首篇突破,荣获AAAI 2023杰出论文奖及IEEE System Journal 2021最佳论文奖,这种卓越的学术表现为工业化加速方案提供了坚实的算法根基。所研发的网络智能管控系统已在中国移动、国家电网、美团、华为等单位的15个省级节点实现规模化工程应用,荣获2023年国家科技进步二等奖和多项省部级一等奖。
02
面向未来的产品推广潜力
针对2025-2026年大爆发的国产化替代趋势,团队的技术方案表现出极高的产品适配性:
跨架构兼容性:HPipe、DeepZoning等框架能够原生支持国产昇腾、海光等异构芯片,解决了“国产算力好买不好用”的难题。
成本效能比:通过 ClusterAttn 和 PICO 技术,团队能够将企业原本需要数百万投资的计算资源需求降低50%以上,具有极强的商业推广价值。
垂直行业渗透:团队在自动驾驶、智慧金融、工业视觉检测等领域的实战经验,确保了技术方案能够快速封装为行业标准化产品。
总结与展望
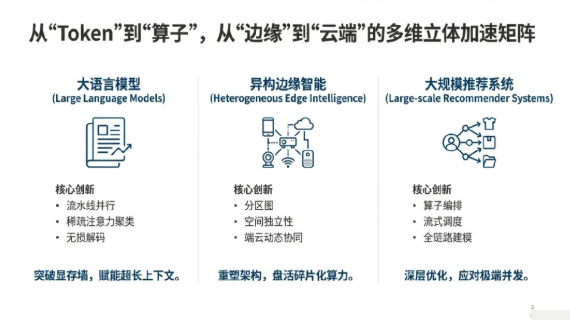
从ClusterAttn中揭示LLM注意力的内在结构,到通过DECC和RACE等技术编排复杂的图计算,我们的工作证明了真正的AI加速来自于在各个层面深度理解并重构系统。AI推理加速是一个复杂的系统工程,需要根据模型结构、硬件环境和应用场景进行“量体裁衣”式的优化。我们团队通过对大语言模型、卷积神经网络以及推荐系统的全方位推理加速研究,构建了从“Token”到“算子”,从“边缘”到“云端”的多维立体加速矩阵。

结语:从理论到落地,加速AI的每一次“思考”。致力于将尖端的学术理论,转化为能够解决工业界实际问题的实用技术。我们坚信,最前沿的科研成果,其最终价值在于弥合学术理论与产业应用之间的鸿沟,解决真实世界中的问题。
END