

公差零界点
在 AR/VR 沉浸式交互、动作识别以及机器人视觉等前沿领域,3D人体姿态估计(3D HPE) 始终是核心技术之一。为了提升精度和鲁棒性,研究者们通常利用多视角系统来获取互补信息 。
然而,传统的“多视角”方案往往面临两大挑战:
相机校准之困:传统方法极度依赖精确的相机参数校准。在动态环境或临时部署场景下,标定过程成本高、灵活性差 。
噪声干扰之痛:虽然“免校准(Calibration-Free)”方法通过数据驱动的方式动态学习视角间的关联,避免了校准难题,但由于缺乏几何约束,模型极易受到遮挡、检测错误等噪声干扰。这些误差会在不同视角间传播和累积,最终导致姿态“崩坏” 。
如何在不依赖相机校准的前提下,让模型拥有对抗噪声的“天然免疫力”?
针对这一挑战,北京邮电大学网络智能研究中心(NIRC) 在人工智能顶级会议 NeurIPS 2025 上发表了论文《Unified 2D-3D Discrete Priors for Noise-Robust and Calibration-Free Multiview 3D Human Pose Estimation》。本文提出了一种创新的 UniCodebook 框架,通过引入统一的 2D-3D 离散先验,该框架在保持连续表征表达力的同时,为模型穿上了一层坚固的“抗噪声铠甲”。
一
痛点:连续表征的“双刃剑”
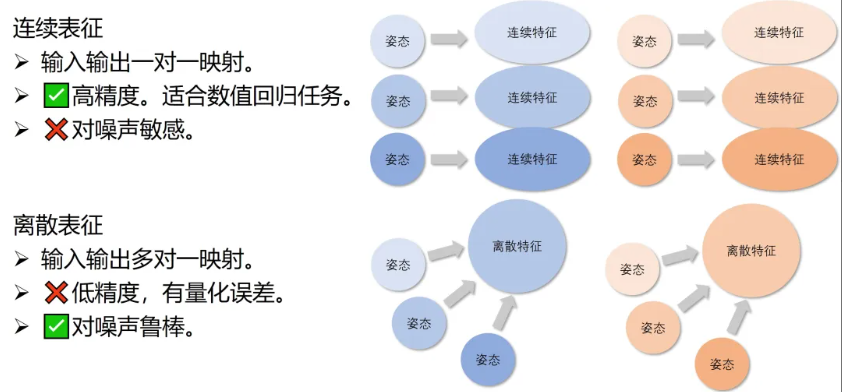
目前 SOTA 的免校准 3D HPE 方案大多基于连续表征(Continuous Representations)。
优点:连续特征空间能够捕捉极其精细的姿态变化,具有极强的表达力。
缺点:由于空间是平滑且无约束的,输入的微小噪声(如2D关节点偏移)会被放大。在多视角交互中,一个视角的噪声可能会传播并污染所有视角,导致最终生成的 3D 人体产生扭曲、折断等不合逻辑的变形。
二
动机:离散表征的噪声鲁棒性
为了解决这一问题,研究团队提出了一个直觉性的动机:利用离散表征的抗噪性来提升对噪声的鲁棒性。
离散表征的天然抗噪属性:离散的码本将连续的姿态映射到有限的“原型(Prototypes)”上。这意味着,只要噪声在一定范围内,它都会被映射到同一个正确的离散 Token 上,从而在表征层面实现“天然去噪”。
人体姿态的先验约束:人体动作是有生物力学限制的。研究团队设计的 UniCodebook 通过学习海量姿态,构建了一个存储“合理姿态”的离散空间。
UniCodebook 的精髓在于:用离散先验作为“锚点”,为连续特征的推演提供几何与解剖学的指引。
三
核心技术:如何融合两个空间?
UniCodebook 并不是简单地将模型离散化,因为离散特征也有自己的优缺点。尽管能提供一定的去噪能力,但离散化的过程损失了精度,这对于姿态估计这样的数值回归任务是不利的。
那如果同时结合连续表征和离散表征的优点呢?研究团队基于此想法,提出以下方法:
主干网络:采用基于连续 Transformer 的模型,以确保高精度的预测。
旁支网络:将离散先验集成到连续回归流程中,在保持回归能力的同时增强鲁棒性。

四
模型细节
整体框架可以清晰地划分为两个阶段:
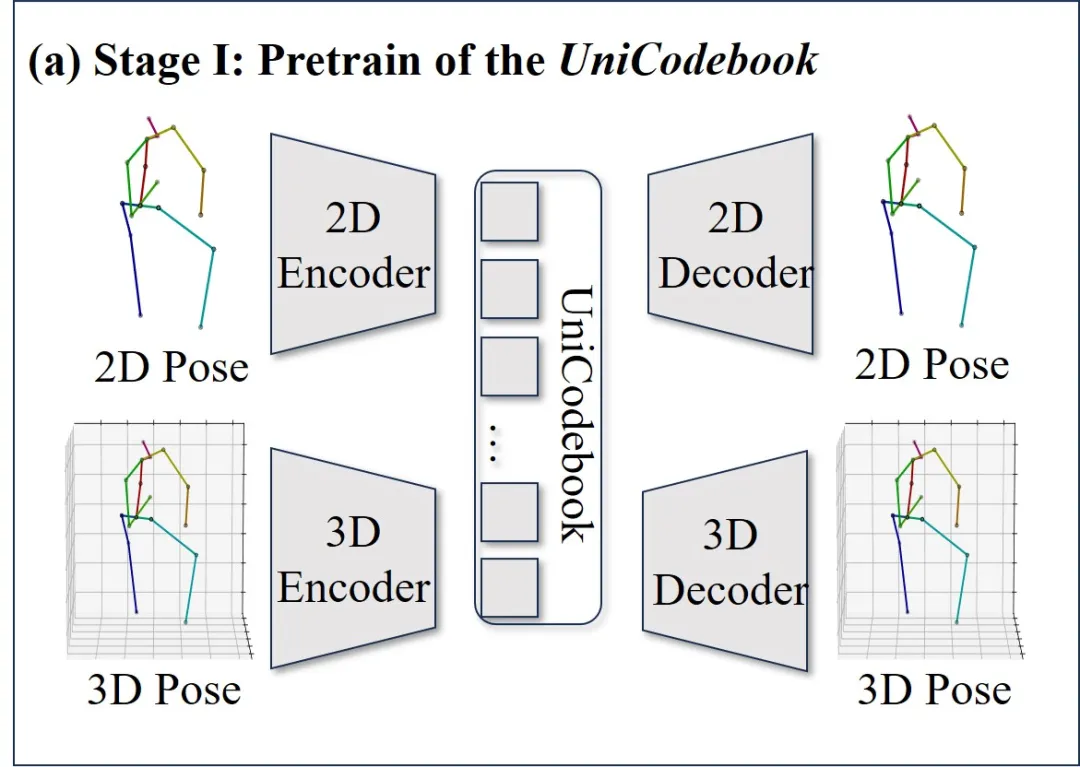
Stage I:先训练一个统一的 2D-3D 离散先验 UniCodebook,让模型掌握人体结构的稳定模式。
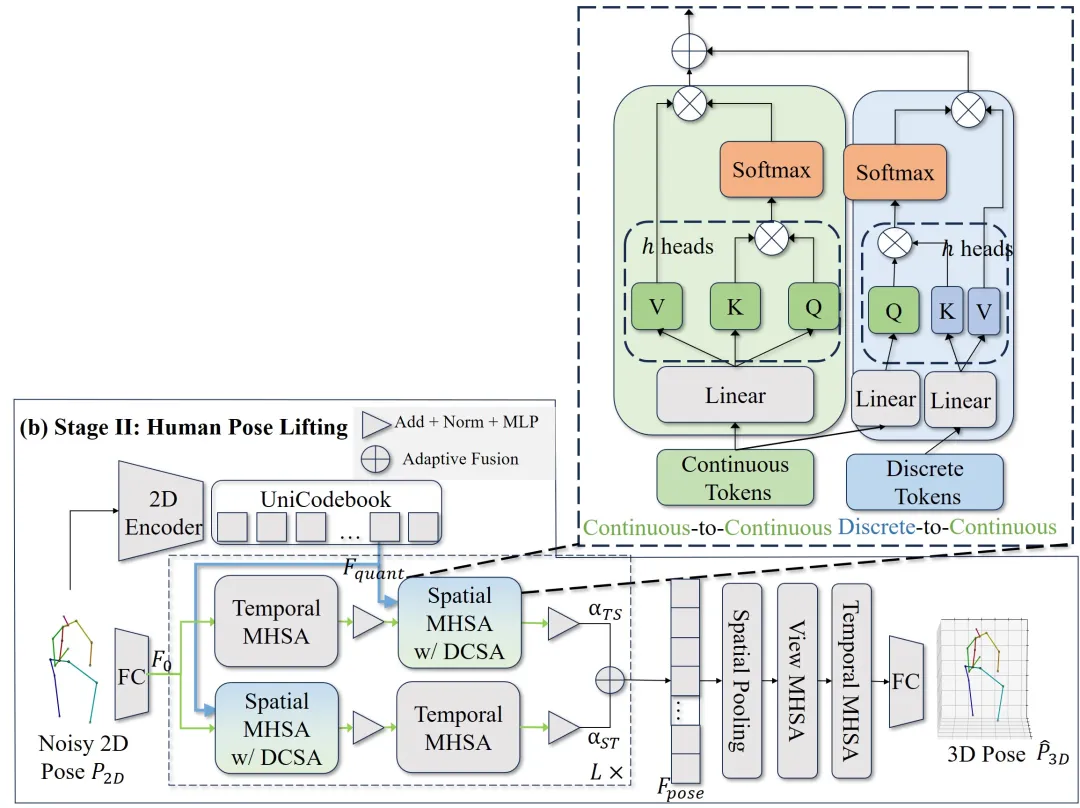
Stage II:做 2D→3D 的多视角 lifting,但把离散先验作为“软指导”注入主 lifting 网络。
01
统一的 2D-3D 离散先验码本训练。
AMAS数据集上,通过2D→2D、2D→3D、3D→2D、3D→3D四种训练策略,学习一个共享的离散码本,统一表示2D和3D姿态,缩小两者之间的表示差距,同时也提高数据的利用率。
02
离散-连续空间注意力机制(DCSA)
2. Discrete-Continuous Spatial Attention (DCSA):离散-连续空间注意力机制。模型不再只进行传统的关节点互相关(Joint-to-Joint Attention),而是额外引入关节到离散原型的注意力(Joint-to-Discrete Token Attention)。实现上,二者分别使用自注意力和交叉注意力实现。
连续流:精细回归的主干。保留 Transformer 的表达能力与细粒度建模优势,确保最后的 3D 回归仍是连续且高精度的。
离散流:噪声鲁棒的结构先验。通过 UniCodebook 把当前姿态映射到离散 token,再作为“结构化记忆”输入注意力模块,让模型获得对遮挡、错检更稳的判断基准。
融合:由连续特征动态选择需要的离散信息。关键是“软注入”:不是把连续特征直接替换成离散特征,而是让连续关节特征在注意力中选择性吸收离散原型信息。
五
实验结果
01
常见基准数据集上的结果
在 Human3.6M 基准上,我们在 CPN 检测 2D 输入 和 GT 2D 输入 两种设置下都取得了 SOTA:分别达到 26.0mm / 7.74mm MPJPE,证明 UniCodebook + DCSA 在保持高精度回归的同时,也能提升跨视角融合质量与稳定性。
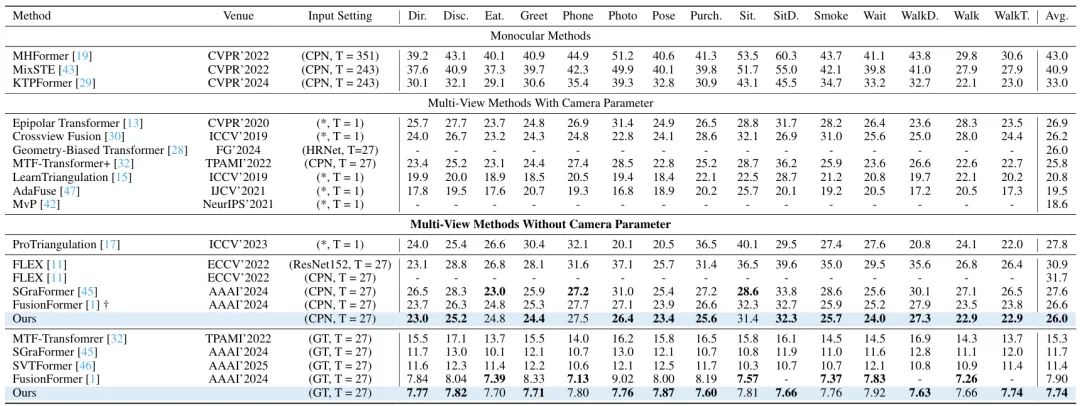
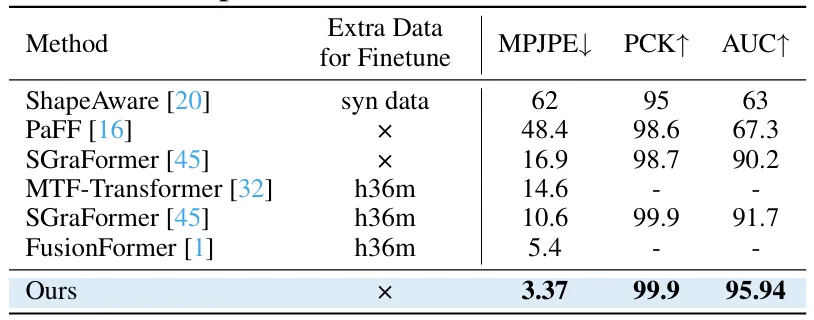
在更贴近真实场景的 MPI-INF-3DHP 上,我们在 不使用额外微调数据 的前提下取得领先:
MPJPE 3.37mm、PCK 99.9、AUC 95.94,在误差与阈值覆盖上均明显优于现有无标定方法,体现了统一离散先验对泛化的帮助。
02
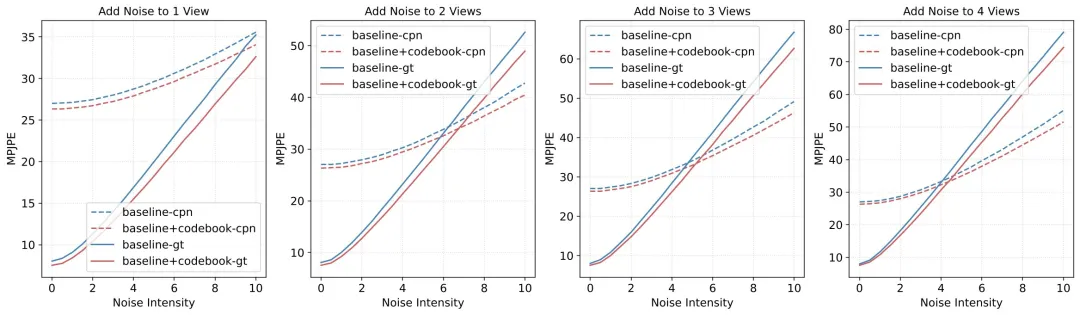
抗噪效果
我们在测试时不重新训练,对随机 1–4 个视角 的 2D 关键点加入不同强度的高斯噪声。结果显示:引入 UniCodebook 的模型在所有噪声强度下都更稳,并且噪声越大优势越明显;说明离散原型能提供结构化“锚点”,有效抑制噪声在多视角交互中的传播与累积。
六
结语
这项研究为多视角3D人体姿态估计提供了一种提升对噪声鲁棒性的新思路。通过离散与连续表示的巧妙结合,不仅提升了模型在噪声环境下的稳定性,也在干净数据上实现了更高的精度。未来,该方法可望在VR/AR、智能监控、运动分析等领域发挥重要作用。
END
笔者简介:陈耿